 釣りキチプログラマー翔平の備忘録
釣りキチプログラマー翔平の備忘録 

はじめに
SSMSでSQL Serverの実行計画を取得〜実行計画の分析〜SQLチューニングの方法についてまとめました。
最近、業務でSQL Serverで4億レコード程の大量データを保持するテーブルに対する
SQLチューニングを行ったのですが、
結構基本的なところで、やらかしてたところだったり、
性能のことを考えてもう少し仕様を考えたり設計すべきだったり、
次回大量データを抱えるテーブル持つときには気をつけようと思うポイントだったり・・・
このあたりについて反省したり学んだことをまとめてみました。
動画でも解説したのでこちらも是非ご覧ください
SSMSを利用したSQL Serverの実行計画の取得方法
まず、SQL Server Management Studio(SSMS)で実行計画を取得する方法ですが、
僕が実行計画を取得する際に使うのは2パターンあります。
クエリを手で流してSSMSで実行計画を取得する方法
SSMSでポチポチやればできます。
実行計画が取得したいクエリをSQL Server Management Studioで実行プランを含めるモードで流せば取得できます。

アプリ起動中に遅いクエリの実行計画を裏で取得する方法
こちらは例えば本番稼働していて、
「〇〇検索機能重いんだけど!!」
というような問い合わせが来たときに、
本番環境で重い検索オペレーションしつつ、裏で実行計画を取るという感じで僕は使っています。
実行計画の取り方としてはクエリを流します。
(僕が作ったわけではないですが、、)このクエリ僕は使いまくってます。
以下参考にしてみてください。他にもこの記事いいこと書いてあるので僕は参考にさせてもらっています。
>>SQLServer: 現在実行中クエリのリアルタイムトラブルシューティング
クエリを流すとこんな感じでquery_plan列がリンクになっているので押すと・・・
(先ほど紹介した「クエリを手で流して実行計画」取得すると、このクエリ取得結果のように
「結果」「メッセージ」「実行プラン」タブが出るのでタブを切り替えれば見れます。
って説明出来てなかった。。。すみません)

実行計画が見れます。
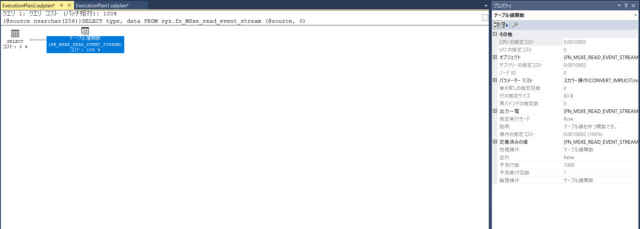
SSMSで取得した実行計画の見方は??SQLチューニングのポイントは??
ではここからはSQLチューニングをする際に、
僕が実行計画のどこに注意してみているのか(クエリの仕様に依存しない一般的な部分を)紹介します。
実際に実行計画を見てチューニングするその前に・・・
該当クエリを見て、この辺りを整理します。
(妄想の時点で実行計画のイメージが掴めないようなら、
SQL Serverも最適な実行計画でクエリ実行できてないでしょうね、、)
- from句をめちゃくちゃネストしてないか??(一時テーブルを先に作ってそれを利用する形にしようかな??)
- テーブルjoinする時のキーは他にも付けることが可能か??(早い段階でデータを絞り込めないか??)
- テーブル結合多すぎる??(非正規化するか??マテリアライズドビュー作る??)
- そもそも仕様複雑すぎる??(仕様の落とし所探る??)
- ざっくりこのクエリの特徴は??(結合テーブル多い??集計が複雑??)
この時点で、今の実行計画を見るまでもなくダメなクエリは先に直しちゃってもいいと思います。
そういうクエリの実行計画を見る意味も対してないし必要以上に複雑だと思いますし。。。
では、ここからは実行計画を見て行きます。
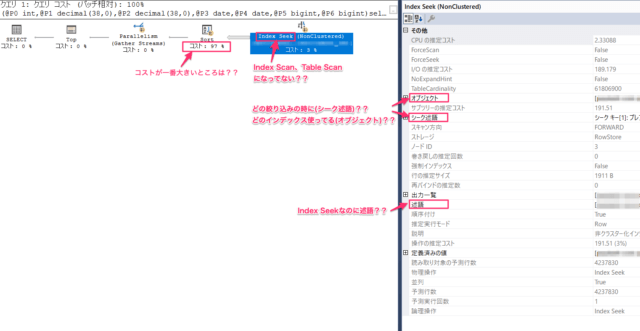
コメントに書いているあたりを僕はとりあえず見ますが、1つずつ解説すると。
コストが高いところから改善する
例ではsortオペレーションのコストが高いです。
このクエリの性能は問題ないのでこれでいいですが、
例えば、これがTable Scanオペレーションでコストが高い場合はIndex貼って
Index Seekにできればクエリ全体としてのコストが大きく減らせる可能性があります。
逆にコストが既に小さいところをいくら改善しても全体としてのコストはさほど減らせません。
インデックス、Index Scan、Index Seekについてここでは説明省略しますが、
こちらで解説しています。
必要であればご覧ください。
 データベースのインデックスの種類と内部の仕組み|SQL Serverで数億規模のデータ量を扱ってみて
データベースのインデックスの種類と内部の仕組み|SQL Serverで数億規模のデータ量を扱ってみて
Table Scan、Index Scanをなくしていく
もし、インデックスを貼っているにも関わらずIndex Seekになっていないオペレーションがあれば
改善する余地があります。
また、想定したインデックスを利用してくれないケースもあったりするので、
その場合、上の例では「オブジェクト」でどのインデックスを利用しているのか??
「シーク述語」でどのwhere条件に対してシークしているのか??を確認するといいです。
想定通りのインデックスを利用してIndex Seekにならないケースとして、業務の中で経験したことですが、
Webアプリから実行するクエリはwhere句の値がパラメータ化されており、
パラメータを全部はめ込んだSQLと実行計画が異なってしまうようなことがありました。
(with句で強制的にインデックスを利用させて一先ず問題を回避したのですが・・・・)
原因は未だに謎です。
クエリが複雑過ぎたり、
統計情報が最新化されてなかったりするとそういうことが発生するので
一先ずその辺りを意識すれば良いかとは思います。
また、これは少しおまけですが、
Index Seekをしているのにも関わらず、
述語が表記されていると、Index Seekをした後、
Index Scanを内部的にしているそうなので、
述語を確認して対策すると改善されることがあります。
Key Lookup、RID Lookupをなくしていく
上の例ではこのオペレーションは既になくしているのでないですが、
これらのオペレーションをなくせると改善が見込めます。
LookupというのはせっかくIndex Seekをして該当データを見つけても
selectしているカラムの情報がB-Treeインデックスに存在せずに実際のデータを
参照しにいくようなオペレーションです。
ここでは詳細な解説はしませんが、
図を使ってこちらで解説していますので、よろしければ参照ください。
データベースのインデックスの種類と内部の仕組み|SQL Serverで数億規模のデータ量を扱ってみて
その対策として付加列インデックスの付加列を追加してやることで
参照オペレーションを減らせて性能が改善が見込めます。
これも僕の業務上での経験の話ですが、
webアプリのコードが短く書けるよう理由でselect * で全項目取得して、
結局ほとんどの項目を利用しない。
しかもそのテーブルが数億規模。というようなことがありました。。。。
そんなことをすると、
付加列インデックスに付加列を全カラム追加、
無駄なリソースを使う、データベースの容量圧迫などなど・・・
悪いことしかありません。
必要な項目だけselectするのはそれだけ基本的で簡単ですが重要です!!!
(ソースが短くなっても諸々コストが膨れ上がることになるのだということに注意です)
まとめ
今回は、SQL Server Management Studioを利用して実行計画を取得し、
SQLチューニングの際に実行計画をどういう観点で見れば良いかについて解説しました。
改めて、チューニングの際に意識するポイントは以下です。
- まず改善対象のクエリを確認して実行計画を見るまでもなく改善できるところはないか確認する
- コストが高いところから改善する
- Table Scan、Index Scanをできる限りなくす
- Key Lookup、RID Lookupをできる限りなくす
- selectする列は必要なものだけやる
最後に・・・
ここまでSQLチューニングについて僕なりのポイントを紹介しましたが、
僕の経験上、現場では、
性能改善の期間はリリース間際ギリギリでほとんど時間が取れないケースが多かったので、、、、
時間をかけずに大幅性能改善が見込める仕様落とす調整をいきなりかけるとかって
裏技も仕方なく使うこともあります。。。(虚しくなります、、)
普段の開発からチューニングの際に意識するポイントを意識して、
性能改善の期間が減らせるのがベストですね。
おまけ
9年間現場で開発に携わってきて、
僕が重要だと考えるデータベース周りの知識に関するまとめ記事を作ったので
是非そちらも参照ください!!


