 釣りキチプログラマー翔平の備忘録
釣りキチプログラマー翔平の備忘録 

はじめに
この記事では、
まずパーティション化する際のメリットと注意点について解説し、
実際にSQL Serverで数億レコード登録されたテーブルをパーティショニング化し、
パーティショニング前後での性能比較検証した結果を実行計画と一緒に紹介します。
テーブルパーティショニング化のメリットと注意点
パーティショニングでは、
論理的に1つのテーブルを、
物理的に小さなテーブルに分割します。
メリットは大きく以下の2つです
データのアクセス範囲が絞り込める
パーティションの分割列を条件に検索する場合
という前提になりますが、
パーティション分割して、
該当パーティションのみにアクセスできるので、
ディスクI/Oが削減できて、
その分検索性能改善を向上させることができます。
これについては、
実際に具体例を使って後述します。
1点だけ注意点としては、
パーティションを跨ぐような検索にはオーバーヘッドかかってくるので、
分割列の選定は該当テーブル検索時、
良く条件指定に利用され、なおかつパーティションを跨がないで済むような列
を選定することに注意してください。
一括削除にかかる運用コストが削減できる
データベースを長期間本番運用する場合、
例えば2年以上前の取引データを削除する。
などを行いつつテーブルのレコード数が増え続けるのを回避したりします。
そのような場合、
DELETEを実行すると、
PostgreSQLだと不要領域が発生してそれをVACUUMたり・・・
そのほかのDBMSでもDELETEに伴いインデックスを更新したり、
といったオーバーヘッドがかかり、
データベースに負荷がかかってしまいます。
テーブルをパーティショニングしておけば、
該当パーティションのテーブルを丸ごとDROPしたりTRUNCATEでき、
DELETE時のオーバーヘッドを減らせて、
データベースにかかる余計な負荷を最小限に抑えることができます。
SQL Serverで数億規模のテーブルをパーティション化して検索性能を前後比較
ここからは、
パーティション化のメリットの一つである検索性能の向上について、
具体的な結果を見ていきます。
現場でちょうど数億規模のテーブルを取り扱っていたので、
以下のようにパーティション化してみました。

このパーティションテーブルに対して、
分割列を条件にシンプルなselect文を投げて、
パーティション化する前後比較結果はこのようになりました。
| 項目名 | パーティション化前 | パーティション化後 |
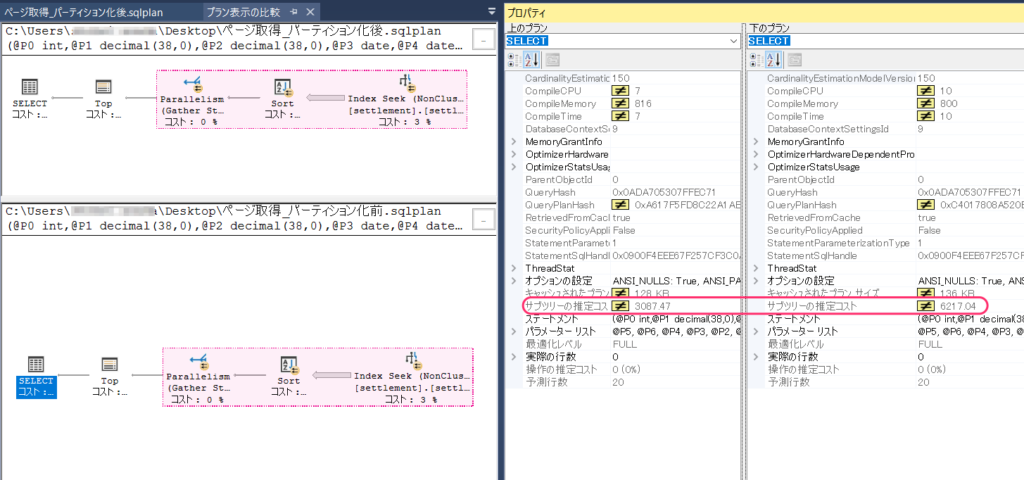
| CPUの推定コスト | 2.33 | 1.15 |
| I/Oの推定コスト | 189.1 | 93.8 |
| サブツリーの推定コスト | 6217.0 | 3087.4 |
| クエリタイム | 7s | 3s |
パーティション化する前からクエリのチューニングはほぼ完璧に行っていたので、
クエリタイムだけ見るとそんなに改善されていないようにみえますが、、、
そこは気にしないでください。
本来なら、数秒しか改善されないのに既存テーブルを性能のためだけにパーティション化し、
移行の労力の割に合わないようなことはしたくないし、すべきではありません。
あくまで今回は、
システムを数年間運用して性能劣化することを想定した検証の位置づけで、
実際この段階で本番適用する予定はありません。
ただし・・・
テーブルの削除サイクル、例えば数年前の取引データは削除などを考えた場合、
取引日時で1つのパーティションに入ってるデータを削除を
高速にできる(インデックス更新などのオーバーヘッドを考えなくていい)
のでその観点ではパーティションテーブルにするのはいいのかも、、、
ちなみにチューニングして、
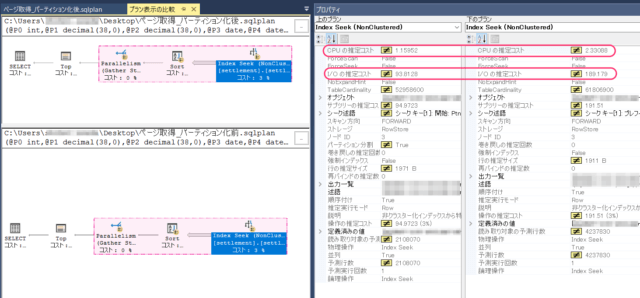
SQLの実行計画を比較する際は上のようにSSMSの比較機能を使うのがオススメです。
クエリプランを開いて右クリック>プラン表示の比較
SQL Serverでテーブルのパーティション化前後比較からわかること
Index SeekオペレーションでのCPUの推定コスト、I/O推定コストが半分になったことから、
同じクエリを実行して同じIndexを利用して、
同じデータを特定するまでのデータアクセス経路が最適化(IO回数削減)されたことが分かります。
こんなイメージです。
元々1つの大きなB-Treeインデックスを辿ってデータを特定していたのを・・・

パーティション化されたB-Treeインデックスの該当パーティションを辿るだけになりました。

そのため、
探索するツリーが分割されて深さが浅くなっているため探索のコストが減りました。
また、
最後のSELECTオペレーションでサブツリーの推定コストが半分になったことから、
Index Seekオペレーションだけでなく
クエリ全体で見てもクエリ実行にかかるコストが半分になったことが分かります。
SQL Serverでテーブルのパーティション化前後の実行計画からわかること
実行計画のコストを見ると、
Index Seekのコストはクエリ全体で見たときに3%です。
本来ならここをいくら最適化したところで性能改善にはならないです。。。。
(今回はパーティション化の検証が目的ですが、
本来はこの実行計画を見たらコストの高いsortオペレーションを最適化すべきです。)
また、
Index Seekオペレーションの「述語」があります。
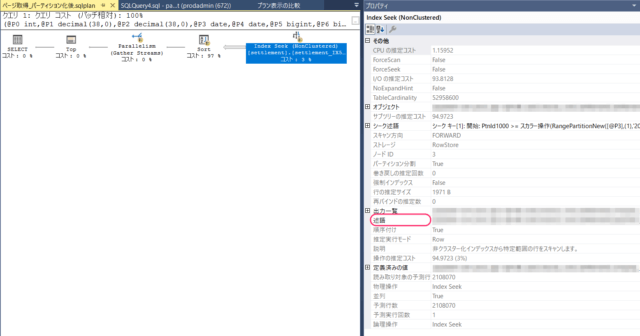
これは、Index Seekした後にIndex Scanしているということです。
こんなイメージ。

もしこれがIndex Seekだけで辿れるようにできるようになれば
さらに性能がさらに改善されるかもしれません。
ちょっと反省
ちなみに、、
これはプロダクトの画面仕様において性能観点での工夫が足りていなかったところですが、
このIndex Scanのkeyになっている項目は画面で検索対象の金額のレンジを設定するものです。
「0円から9999999円の取引データを検索対象に絞り込む。」
みたいなイメージ
しかも、画面仕様として初期値で金額スパン0円から9999999円に設定されます
(where句に金額スパンを条件指定する必要がないのに毎回指定している)。
それによって、
ユーザは実際にスパンを絞り込む必要がなくても
無意識にこの設定で検索していることがほとんど。。。
初期値は金額スパン設定なしで、絞り込みたい時だけ入力させるような画面仕様にしておけば、
インデックスを付与するカラムからこの項目はホントなら外せて、
Index Seekの後にIndex Scanするようなこともなかったと反省しています。
前提:よく使われる検索条件だけクエリの性能を最適化させ、
オンラインアプリに必要なインデックス作成を最低限にすることで、
夜間大量データバッチ処理での登録更新処理性能を優先させる方針
まとめ
SQL Serverでテーブルをパーティション化して、
前後比較してみての結果をまとめました。
クエリを爆速にすることはできませんでしたが、
パーティション化することで以下が分かりました。
- テーブルをパーティション化することでIndex Seekにかかるコストを半分くらいまで減らせる。
- 画面仕様を工夫(金額スパン常時指定外す)することで性能改善ができそう。
ただ、
既に本番運用しているテーブルを後からパーティショニング化するには、
かなりの労力がかかるので、
パーティショニング化の検討はお早めに・・・
大量データを保持するテーブルを運用する際に、
この記事が参考になれば幸いです。
10年間の現場でのアプリケーション開発経験から、
現場経験を現場で役立つデータベースのまとめ記事を作成したので、
是非そちらも参考にしてみてください。
 初めてデータベースを触る方に向けて〜新人プログラマー時代の自分に伝えたいこと〜
初めてデータベースを触る方に向けて〜新人プログラマー時代の自分に伝えたいこと〜 
